Not registered? - Request an account here

REID2017 ICDAR Competition on Recognition of Early Indian printed Documents
Overview
The British Library is currently undertaking a ground breaking project, Two Centuries of Indian Print, to digitise and make available as open access 4,000 early printed Indian books (1713-1914) written in Bengali. Complementary material, the Quarterly Lists, consist of catalogue records for all books published in India between 1867 and 1967, will also be made openly available through the project.
As part of this project we would like to pose a challenge to find an optimal solution for accurately and automatically transcribing the Bengali books and Quarterly Lists, to form a unique dataset that can be used with computational tools and methods, and to enable full-text search and discovery.
| Challenge 1 | Recognition of multi-lingual tabular data (English, Bengali) | 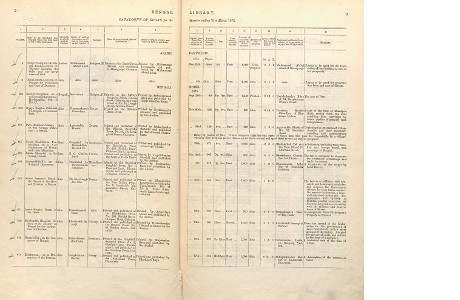 |
| Challenge 2 | Recognition of Bengali books |  |
Here is a short YouTube video with the essentials.
Sharing accurate transcriptions of the books will greatly benefit the scholarly research community in performing large-scale analysis of the material to reveal new insights into book and publishing history in India. Much of the material up until now has only been accessible in physical form by visiting the Library.
The ICDAR2017 Competition on Recognition of Early Indian printed Documents (REID2017) follows the successful running of all previous ICDAR Layout Analysis and Recognition competitions - some of which focused on historical documents (2001, 2003, 2005, 2007, 2009, 2011, 2013, and 2015). The proposed competition will build upon the challenges of the previous competitions, with a new unique dataset and an end-to-end workflow scenario.
Challenges
This competition is split into two tasks, the first to tackle the Quarterly Lists, the second to address the Bengali Books. Entrants are welcome to address either one of the challenges, or both.
Challenge 1 – Recognition of Multi-Lingual Tabular Data
The Quarterly Lists were produced between 1867 and 1966 as catalogue records of books published in India. They contain bibliographical information about the books, such as the title, author and address of printer. They amount to 250 separate lists, scanned as c.125,000 pages/TIFF files. Although most of the written content within the lists is in English-language, many contain a small amount of Bengali - usually the titles of books. The layout of the lists is a particular challenge we would like to overcome. The Quarterly Lists consist of several different layouts of tabular data, which have been represented in the sample set. Most pages contain several columns of text, which often run between columns and over multiple lines within columns. An OCR solution that can effectively identify the region of text within these tables will enable researchers to accurately parse the data to identify particular categories of information and carry out digital research. Therefore, handling these layout challenges will be crucial to the success of entries. Dealing well with the instances of Bengali text will also count to the success of submitted OCR results.
Challenge 2 – Recognition of Bengali Books
As part of our digitisation project, we will be digitising 4,000 printed books, which will amount to c.800,000 pages in TIFF format. The text of these books is in Bengali language dating between 1785 and 1909. For the most part, the scanned images contain single column lines of text, with a small amount containing illustrations as well as text. Some pages also contain marginal data such as numbers. Accurately capturing content from title pages of books presents yet another challenge.
Dataset and evaluation methodology
The dataset to be used in this competition will be a subset of the publicly available digitised documents at the British Library related to the Two Centuries of Indian Print project. The dataset contains documents reflecting various challenges in layout analysis and text recognition. Ground truth will be available in the PAGE format.
The competition will use the comprehensive evaluation approach successfully employed in recent ICDAR competitions. It has been recently extended to perform text-based evaluation (e.g. for OCR) as well. As a whole, it takes into account a wide range of situations and provides considerable details on the performance of different methods. Each type of error is weighted according to the type of regions involved and the situation they are found. The evaluation tools used are freely available from the PRImA website.
Participating systems will be evaluated in different stages (i.e. segmentation, classification, recognition) according to how far their methods are applicable within the analysis and recognition workflow – not all participating systems have to be end-to-end applications. The organisers will offer assistance to participants on how to integrate an open-source OCR module into their workflow.
In addition to the accuracy of their results, the submitted systems will also be evaluated on the scalability of their proposed solution to be implemented across the entire collection (as described earlier).
Additional information
Participants will be provided with a number of tools developed by PRImA that can be used in order to prepare and optimise their method(s) for submission (as well as to examine the example set in detail). They will also be supported in implementing the required output format by means of PAGE exporter modules (C++ or Java) and additional information about the underlying XML Schema.
The winning entry will be invited to write a short article for the Two Centuries of Indian Print website describing their work.